What Python’s [[]] * 10 Really Does: A CPython Deep Dive
A deep dive into Python's list creation mechanics: explore how multiplication creates shared references while list comprehensions create independent objects by examining the actual CPython implementation code.
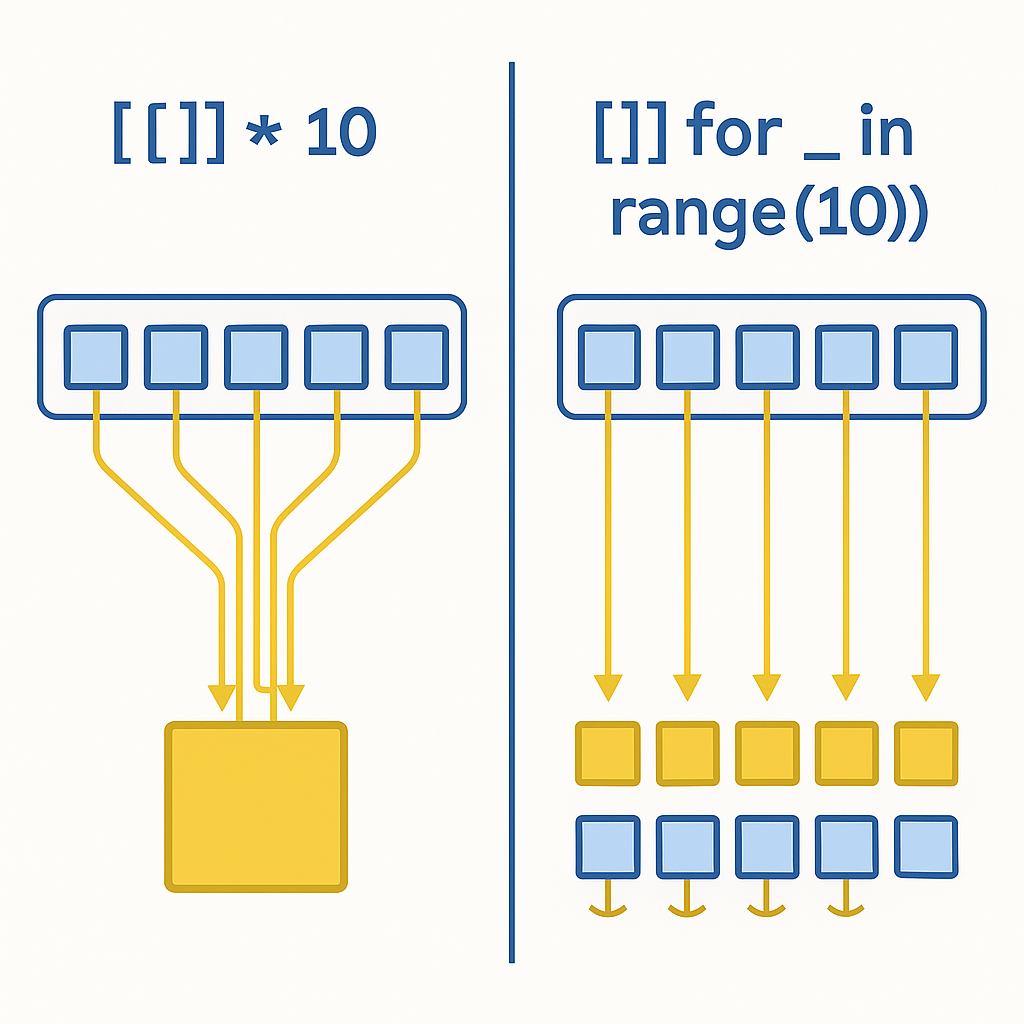
Python List Multiplication: Not What You’d Expect
I have a habit of avoiding syntactic sugars of Python unless absolutely necessary or if I’m feeling lazy! It’s not like I have a bad opinion of them. I think some of them are highly optimized which could help you leverage the unique features and efficiency of Python where it matters.
Recently I was writing a script where I decided to use this syntactic sugar of Python which I assumed would create a list of lists. Well, to be fair, it does… just not in the way I expected.
Expected vs. Actual Results
Let’s look at this seemingly innocent piece of code:
1
2
3
list_of_lists = [[]] * 10
list_of_lists[0].append(1)
print(list_of_lists)
What I Expected
I assumed that the above code would result in the first sublist having a single element appended to it like:
1
[[1], [], [], [], [], [], [], [], [], []]
What Actually Happened
But to my surprise, it resulted in this:
1
[[1], [1], [1], [1], [1], [1], [1], [1], [1], [1]]
Well, it was in a subroutine which was doing many other things, so it took me a while, but it was not long before I figured out that all of these lists pointed to a single memory address. As verified by the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> register = [[]] * 10
>>> for i in range(10):
... print(id(register[i]))
...
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
1728395547200
It all made sense, but I had this itch to see how it was really implemented under the hood. So I did what any productivity guru and pragmatic person would tell you to do:
Checkout the Python Interpreter Source Code 😤
Diving into the CPython Codebase
I headed over to the cpython repo on GitHub to investigate how list multiplication actually works.
In CPython, there are two methods in listobject.c that are responsible for creating the list when you write the list multiplication syntax like [[]] * 10.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
static PyObject *
list_repeat_lock_held(PyListObject *a, Py_ssize_t n)
{
const Py_ssize_t input_size = Py_SIZE(a);
if (input_size == 0 || n <= 0)
return PyList_New(0);
assert(n > 0);
if (input_size > PY_SSIZE_T_MAX / n)
return PyErr_NoMemory();
Py_ssize_t output_size = input_size * n;
PyListObject *np = (PyListObject *) list_new_prealloc(output_size);
if (np == NULL)
return NULL;
PyObject **dest = np->ob_item;
if (input_size == 1) {
PyObject *elem = a->ob_item[0];
_Py_RefcntAdd(elem, n);
PyObject **dest_end = dest + output_size;
while (dest < dest_end) {
*dest++ = elem;
}
}
else {
PyObject **src = a->ob_item;
PyObject **src_end = src + input_size;
while (src < src_end) {
_Py_RefcntAdd(*src, n);
*dest++ = *src++;
}
// TODO: _Py_memory_repeat calls are not safe for shared lists in
// GIL_DISABLED builds. (See issue #129069)
_Py_memory_repeat((char *)np->ob_item, sizeof(PyObject *)*output_size,
sizeof(PyObject *)*input_size);
}
Py_SET_SIZE(np, output_size);
return (PyObject *) np;
}
static PyObject *
list_repeat(PyObject *aa, Py_ssize_t n)
{
PyObject *ret;
PyListObject *a = (PyListObject *)aa;
Py_BEGIN_CRITICAL_SECTION(a);
ret = list_repeat_lock_held(a, n);
Py_END_CRITICAL_SECTION();
return ret;
}
Breaking Down the Implementation
Okay, enough of Egyptian Hieroglyphics, let’s come to the point. What is it actually doing?
When evaluating [[]] * 10, the list_repeat function is called.
Here,
PyObject *aa=[[]](our list containing one empty list)Py_ssize_t n= 10 (our multiplier)
First, we initialize our return value and typecast the input:
1
2
PyObject *ret;
PyListObject *a = (PyListObject *)aa;
- This declares a new
PyObjectfor returning - Creates a
PyListObjectand typecasts the existing*aaparameter toPyListObject
Next, we call the actual implementation:
1
ret = list_repeat_lock_held(a, n);
Inside the list_repeat_lock_held Function
Initial Checks and Memory Allocation
1
2
3
4
const Py_ssize_t input_size = Py_SIZE(a);
if (input_size == 0 || n <= 0)
return PyList_New(0);
assert(n > 0);
First, we determine the size of our input list. If the size is 0 or the multiplier is less than or equal to zero, we just return an empty list.
This means if you had performed [] * 10 or [[]] * 0 or [[]] * -29, the result would be [].
Let’s verify:
1
2
3
4
5
6
7
8
9
10
>>> [] * 10
[]
>>> [[]] * 0
[]
>>> [[]] * -29
[]
>>> [] * 0
[]
>>> [] * -9888
[]
Indeed, we get a single newly created Python list of length 0!
Next, we have a defensive check to prevent integer overflow:
1
2
3
if (input_size > PY_SSIZE_T_MAX / n)
return PyErr_NoMemory();
Py_ssize_t output_size = input_size * n;
Here, PY_SSIZE_T_MAX is the max value of a long int, which is typically 9223372036854775807 on a 64-bit machine.
The same is accesible through sys.maxsize in Python.
1
2
3
>>> import sys
>>> sys.maxsize
9223372036854775807
After our defensive check, now it’s time to allocate memory for our new list object:
1
2
3
PyListObject *np = (PyListObject *) list_new_prealloc(output_size);
if (np == NULL)
return NULL;
The list_new_prealloc function might return NULL if our output_size is negative:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static PyObject *
list_new_prealloc(Py_ssize_t size)
{
assert(size > 0);
PyListObject *op = (PyListObject *) PyList_New(0);
if (op == NULL) {
return NULL;
}
...
}
PyObject *
PyList_New(Py_ssize_t size)
{
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
...
}
The Critical Part: How Python Copies the References
Now we come to the main part where the list is actually made and returned to the user:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PyObject **dest = np->ob_item;
if (input_size == 1) {
// Single element list case
PyObject *elem = a->ob_item[0];
_Py_RefcntAdd(elem, n);
PyObject **dest_end = dest + output_size;
while (dest < dest_end) {
*dest++ = elem;
}
}
else {
// Multi-element list case
...
}
The Single Element List Case (Our [[]] * 10 Example)
Since our list [[]] has only one element (which is the empty list []), we enter the input_size == 1 branch:
1
2
3
4
5
6
PyObject *elem = a->ob_item[0];
_Py_RefcntAdd(elem, n);
PyObject **dest_end = dest + output_size;
while (dest < dest_end) {
*dest++ = elem;
}
Let’s break down what’s happening:
- We select the first element of the list:
elem = a->ob_item[0](this is our[]empty list) - We increase the reference count of this element by n (10 in our case):
_Py_RefcntAdd(elem, n) - We calculate the end pointer for our destination array:
dest_end = dest + output_size - We run a simple loop that copies the same reference to each position in our new list
This is the key insight! The function doesn’t create 10 new empty lists - it creates one new list with 10 slots, and puts the same empty list reference in each slot!
Python’s Reference Counting System
Let’s take a small detour to understand reference counting in Python, as it’s crucial to understanding what’s happening here.
In Python, every object (PyObject) internally has an unsigned 32-bit integer property ob_refcnt to track how many references are tied to this particular object.
For example, if I have an object snow_bell of Cat class:
1
2
3
4
5
6
7
8
9
>>> class Cat:
... def __init__(self, name):
... self.name = name
...
>>> snow_bell = Cat("Snow Bell")
>>> import sys
>>> sys.getrefcount(snow_bell)
2
sys.getrefcount shows us the internal reference count of an object. It says 2 because:
- We have the reference
snow_bellvariable - The
getrefcountfunction itself creates a temporary reference to the object
When the reference count reaches 0, the object is garbage collected.
Did you know?
In Python, some objects are immortal — they’re never garbage collected. This includes
None,True, andFalse. Interestingly, under certain conditions, even a seemingly ordinary object can become immortal.If you’re curious, check out the source code of
_Py_RefcntAddto dig deeper. But that’s a topic for another article.
Back to Our List Multiplication
So when we run [[]] * 10, what happens is:
- We create one empty list
[] - We put that same list reference in 10 different slots of our new list
- When we modify
list_of_lists[0], we’re modifying the same list object that all 10 slots refer to!
The Multi-Element List Case
For completeness, let’s examine what happens with multiple elements. For example, [[10], [20]] * 10:
1
2
3
4
5
6
7
PyObject **src = a->ob_item;
PyObject **src_end = src + input_size;
while (src < src_end) {
_Py_RefcntAdd(*src, n);
*dest++ = *src++;
}
_Py_memory_repeat((char *)np->ob_item, sizeof(PyObject *)*output_size, sizeof(PyObject *)*input_size);
In this case:
- The function first copies references to
[10]and[20]into the first two slots of our new list - It then uses
_Py_memory_repeatto efficiently duplicate these references throughout the rest of the list
The _Py_memory_repeat function is particularly clever - it doubles the copied region in each iteration, making it logarithmically efficient:
1
2
3
4
5
6
7
8
9
10
11
static inline void
_Py_memory_repeat(char* dest, Py_ssize_t len_dest, Py_ssize_t len_src)
{
assert(len_src > 0);
Py_ssize_t copied = len_src;
while (copied < len_dest) {
Py_ssize_t bytes_to_copy = Py_MIN(copied, len_dest - copied);
memcpy(dest + copied, dest, (size_t)bytes_to_copy);
copied += bytes_to_copy;
}
}
-
The variable
copiedtracks how many bytes of repeated content have already been written. It starts atlen_src, the length of the original pattern. -
bytes_to_copyis calculated usingPy_MIN(copied, len_dest - copied). Ideally, you’d like to double the data by copyingcopiedbytes, but if that would go beyond the destination buffer, it’s capped at the remaining space. -
The actual copying happens with
memcpy(dest + copied, dest, bytes_to_copy). This means you’re copying from the beginning ofdest(which already contains some repeated pattern) and appending it to the end of the currently copied region. This effectively doubles the region that now holds the repeated content. -
After copying,
copiedis incremented bybytes_to_copy, and the loop continues until the entire buffer is filled.
This approach is clever because it builds on the already-copied data. Instead of repeatedly copying from the original source, it uses the growing buffer itself to continue the repetition. The number of copied bytes grows like this: len_src -> 2*len_src -> 4*len_src -> ..., until the full destination length is reached.
So What About [[] for _ in range(10)]?
In case you’re wondering why I didn’t touch on the [[] for _ in range(10)] approach - well, when I started writing this article, I kept digging deeper and deeper into the amazing mechanics of the Python interpreter. It was as much of an adventure for me as it has been for you!
I realized that the article is already too long, so our list comprehension approach deserves its own separate article. The key difference though? In list comprehension, each iteration creates a NEW empty list, rather than referencing the same one multiple times.
Conclusion
So there you have it - a deep dive into how Python’s list multiplication works under the hood. The next time you use [[]] * 10, you’ll know exactly what’s happening and why modifying one sublist affects all of them!
Enjoy your Coffee ☕
Let me know what you thought about this article. Would love to know your opinions… Feel free to reach out via email.